On and off over the past year I’ve been working with Jason Baron on a design for a UI for system administrators to control processes’ and users’ usage of system resources on their systems via the relatively recently-developed (~2007) cgroups feature of the Linux kernel.
After the excitement and the fun that is the Red Hat Summit, I had some time this week to work with Jason on updating the design. Before I dive into the design process and the mockups, I think it’d be best to do a review of how cgroups work (or at least how I understand them to) so that the rest makes more sense. (And maybe I’ve got some totally incorrect assumptions about cgroups that have resulted in a flawed design, so hopefully my calling out the current understanding might make it easier for you to correct me ![]() ).
).
A designer’s understanding of cgroups via diagram
So cgroups, which are sometimes referred to as containers (I think because a similar Solaris feature, zones, is sometimes called containers) can be used to slice an entire operating system into buckets, similarly to how virtual machines slice up their host system into buckets, but without having to go so far as replicating an entire set of hardware.
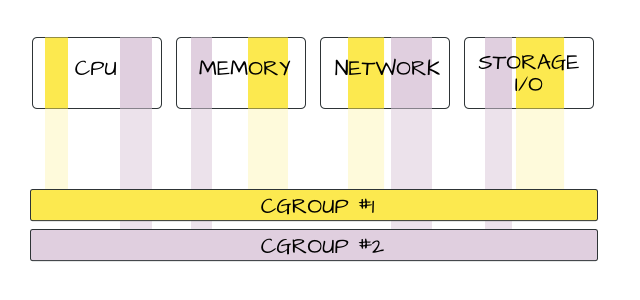
So this diagram kind of shows how four of the system resources that cgroups can control – CPU, memory, network, and storage I/O – could be cut into slices that are then combined into two groups – the yellow and the purple one – which make up virtual OSes. Say I gave cgroup #1 (yellow) to Sally, and cgroup #2 (purple) to Joe. Whenever Sally starts a process, you could set it to only run on the CPUs that are members of cgroup #1 (via cpuset), at whatever priority level is set for those CPUs (via cpu). It’ll only be able to use as much memory as was allocated to cgroup #1, only be able to use as much network and I/O bandwidth as cgroup #1 is able to use. When Joe starts a process, because he’s part of cgroup #2, he won’t be using the same CPUs as Sally. He may have more or less memory, I/O, and network bandwidth allocated to him.
It’s kind of / sort of like Joe and Sally are using different computers, on the same operating system. Cool, right?
Cgroups don’t have to go that deep, though. You don’t need to slice across an entire system.
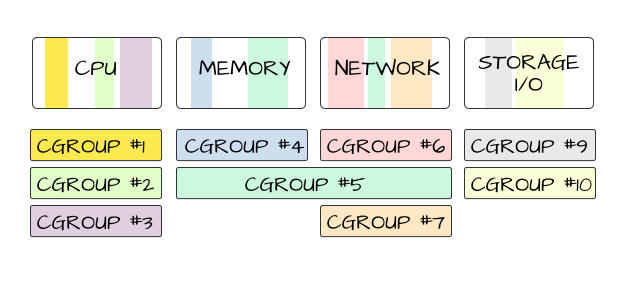
You can have a cgroup that *just* deals with controlling access to the CPU. Or *just* controls memory. Or maybe only deals with two of the four (CPU, Memory, Network, I/O) resources, or just three of the four.
You can have a cgroup that *just* deals with one resource (say CPU), and that group only deals with specific processes. Or users. Or a combination thereof. (More later on that.)

Depending on the resource you’re looking to control and the cgroups module you’re using, you can configure access to that resource in different ways. I believe one of the more common ways of controlling CPU usage via cgroups is to assign ‘shares’ for various groups’ usage of the CPU (using the ‘cpu’ module.) I’m not sure what scale/units these shares are on, but they are relative to each other, so if I give group #1 a weight a 1024, and group #3 a weight of 2048, then group #3 will get scheduled for CPU time twice as much as group #1 will.
I don’t think this share system is particularly intuitive, which is still an open problem in the current draft of the UI design.
Other resources and modules let you control access in different ways. For example, the memory module lets you configure an upper bound of memory usage, I believe via providing the maximum number of bytes of memory that could be used by members of the group.
You can create and apply cgroups to processes and users on-the-fly or on a longer-term / persistent basis. Say some process is running amok and is starving other processes on your system… you can change the process’ cgroup membership on-the-fly to provide it a more limited set of system resources so that other processes on the system can run. However, this change would be temporal and may be based, for example, on a specific pid number that won’t apply if the process is restarted or the system is rebooted. If you’d like more persistent cgroup membership, you can create a set of rules (cgrules.conf). A neat simple thing you could do with cgroup rules, for example, is something mentioned by Linda Wang in her Red Hat Summit talk on cgroups; you could arrange your cgroups rules such that the sshd always gets a dedicated chunk of CPU time so that if a process runs amok on a server system, you still might be able to ssh in remotely to diagnose the problem.

It’s via these rules that you can set up persistent groups on the system. It would be kind of a pain to have to set them up every time a system is rebooted, especially the more processes and users you’re managing, and the more groups you need to create in order to manage them. You can use multiple cgroups modules (for example, cpu, cpuset, mem, net) within a single cgroup, and then write rules to place processes run by particular users and/or user groups into the cgroup, or write rules to place processes matching particular attributes into the group.
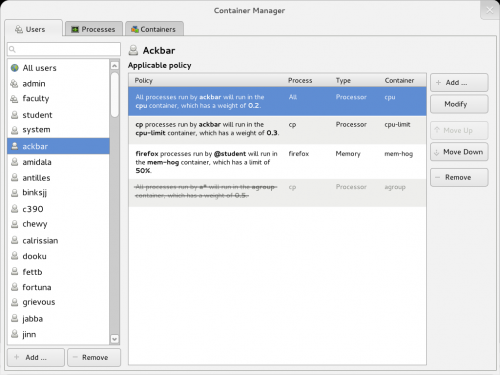
Above is a diagram demonstrating a cgroup that restricts only CPU usage for processes matching firefox-*, npviewer.bin run by users that are in the ‘guest’ group or whose usernames are ‘student1′ or ‘student2′. Kind of putting it all together, showing a single group and its resource allocation, and its associations with particular users and processes.
Who would use a UI for this, and why?
Tthe UI design mostly focuses on setting up persistent rules, and doesn’t really allow for on-the-fly cgroups rearrangement of currently-running processes and currently-logged in users. The thinking behind this is that there might be a couple of main reasons you’d be using a UI for cgroups:
- Proactive: Initial system resource allocation planning
- Reactive: In response to a complaint – ‘My processes are getting capped,’ or ‘Such-and-such process isn’t running right.’
Thinking about the way my previous experience with system administrators has typically gone, there’s sadly not usually a lot of time for proactive planning and organization – a majority of time tends to get spent on reacting to client concerns. If someone is calling you up on the phone to tell you that a process they are relying on has gone awry, it seems the most effective way to get them to stop calling you would be to change the rules to make a more persistent change to help them, rather than to just apply a change on the fly and wait for their next phone call. ![]() So I think you’d probably prefer to change rules in reaction to a client complaint, not just do an on-the-fly change (although you could.) When you’re being proactive and initially setting up a system, I think you’d not want to do that on-the-fly at all, because you’d have to keep reapplying. It’d be better to craft a set of rules to persist on the system.
So I think you’d probably prefer to change rules in reaction to a client complaint, not just do an on-the-fly change (although you could.) When you’re being proactive and initially setting up a system, I think you’d not want to do that on-the-fly at all, because you’d have to keep reapplying. It’d be better to craft a set of rules to persist on the system.
So it seems like these two main use case types – proactive resource allocation, and reactive allocation adjustments based on client feedback – are both best served by focusing on rules, so that’s why the UI design only focuses on those.
Maybe there is a case for doing the on-the-fly stuff though. It does make for some pretty awesome demos, though, like the one Bob Kozdemba gave at the Red Hat Summit last Friday, moving multiple copies of a graphics rendering tool between cgroups and vms and changing their configuration on the fly so you could visually see the affect of resource caps on the processes.) You could also use the on-the-fly configuration changes to test out a theory about how you should set the rules.
So, specifically, what kinds of problems could we imagine a user looking to solve with this interface? Our thoughts were that most likely a system administrator would find it most useful:
Under the ‘Proactive’ Category:
- I have a system running a business-critical app that sadly has a memory leak, and I want to make sure that app doesn’t screw up the other apps running on the system. I’d like to put a cap on its memory usage so when it goes down it doesn’t take the rest of the system down with it.
- I have a thin-client lab meant for the use of students in the science department, but students from other departments are allowed access via guest accounts. I’d like to make sure the guest accounts don’t block any of the science department students’ work on the server.
- I’m an administrator at an ISP and we provide virtual machines to end users in different pricing tiers. I’d like to enforce the limits set by our pricing tiers so that customers’ VMs aren’t getting more power than they are paying for and aren’t starving customers that are paying for more power.
Under the ‘Reactive’ Category:
- A student from the science department has called helpdesk to complain that his simulations don’t have very much oomph and are taking far too long to run. I need to figure out what system resource policy might apply to this user, and make modifications to his policy as needed to help him out if possible. (For example, perhaps he was previously outside of the science department and just transferred in, so he’s still running in the guest group.)
- Uh-oh, something’s gone wrong. A business critical process keeps getting OOM’ed! I need to figure out what resource allocation policy applies to it to see if there a rules that are causing the issue / that could be adjusted to get the app running consistently again.
- Our bi-weekly payroll processing application is still going full-steam ahead but it’s Monday morning, the business day is starting, and that server needs to be used for other things. Whoops, that’s never happened before, it usually finishes on Sunday. I need to see what policy applies to it, and modify our rules so that the payroll process tones things down a bit if it hasn’t finished over the weekend.
The mockups
So after a lot of sketching, crossing out, sketching, crossing out, and thinking about the above types of use cases, we thought to break up the main window in this way:
- A users tab: For when you have a specific user/group in mind you’d like to limit, or if you’ve got a specific user on the phone who you’re trying to troubleshoot with;
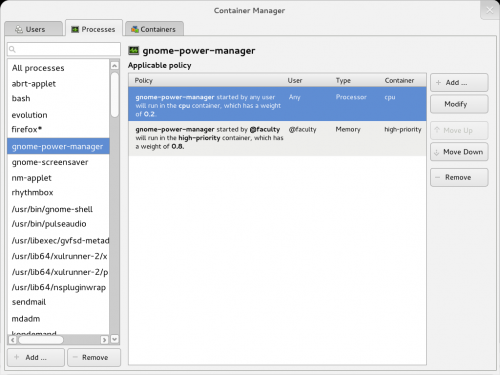
- A processes tab: For when you have a specific process in mind you’d like to limit, or if you’ve got someone on the phone upset about a particular process you need to help debug;
- A containers tab: For when you need to initially create your cgroups, or if you’d like to tweak the configuration of a particular group, or if you’d like to see how the processes within the group are performing.
So here’s what they look like:
The users tab
The processes tab
The containers tab
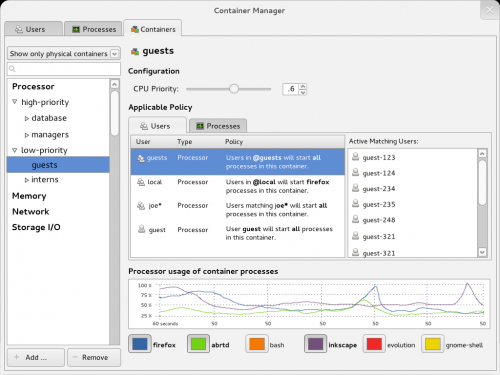
Some issues / further work
Here’s a bit of a braindump of where these need more work:
- So I mentioned in one of the example use cases a payroll application, that could run full steam during the weekend but had to be dialed back during the work week. Well – this UI design doesn’t account for scheduling in the rules, yet.
- There’s no mockups for the various dialogs needed for adding and modifying rules.
- It would be cool to do a mockup showing how this might integrate into the GNOME system monitor – maybe an additional filter on it?
- It would also be cool to have some kind of integration with the user accounts dialog. Maybe it’d show the policy that applied to a user and let you modify it from that dialog?
- Right now in the containers tab, we had the idea to list the containers by the resource they are managing – so groups involving cpu, cpuset, cpuacct for example would all be listed under a ‘CPU’ category. However, Jason had an idea about showing logical cgroups that span resource types – e.g., you might have a cgroup tuned for DB usage with different settings for CPU in combination with memory & I/O.
- The users and processes tab doesn’t really let you monitor resource usage per user / per process. Is that needed? Not sure.
- Units – shares vs upper limits vs… the actual numbers you’re configuring for each rule need to be fleshed out. If cpu / cpuset / cpuacct for example can be used in conjunction, how would that be shown in the UI?
- What about a mechanism to compare effective resource allocation vs actual resource usage? So you could see, ‘hey, this process is starved, maybe we should consider upping it,’ or ‘hey, this user isn’t really coming anywhere near their limits, should we dial them down?’ An earlier draft of the mockups showed graphs of each for comparison.
- (Edit: idea from Bill Nottingham) Support multiple systems in one UI over the network
The wiki page for this design (including Inkscape SVG sources) is here:
http://fedoraproject.org/wiki/Design/CGroupsUI
Feedback
Is this nuts? Does it make sense? Is this the wrong approach? Do you use cgroups? Would this be a useful tool, or does it suck?
I hope you’ll let us know.
Filed under: cgroups, Fedora, Interaction Design, Interaction Design Work






















